News Sentiment Showdown: Who Checks Vibes Best?
A comparison of sentiment classifications made by TextBlob, VADER, Flair, SigmaFSA, FinBERT, FinBERT-Tone, Text-Bison, Text-Unicorn, Gemini-Pro, GPT-3.5, GPT-4, and GPT-4-Turbo. We look at accuracy, time, and cost and include a dataset of 10,368 labelled news stories (with code) for our followers.


One of our goals for 2024 is to extract investment signals from our growing corpus of verified company news. Last week in the post, "Using Vector Search to See Signals in Company News" we focused on news volume. This week we are going to dive into another dimension we care about: Sentiment.
To put it simply, sentiment is how positive or negative the view expressed towards the object or subject of a document is. Quant funds around the world have long been interested in how to quantify sentiment, how sentiment changes over time, and whether it correlates to future market performance.
Today we will focus on the first question: "How can sentiment be quantified?". In this post we will compare TextBlob, VADER, Flair, SigmaFSA, FinBERT, FinBERT-Tone, PaLM-2 (Bison and Unicorn), Gemini-Pro, GPT-3.5, GPT-4, and GPT-4-Turbo. In the future we will add more models to the mix.
To start off, we compare these models against 250 hand labelled news stories. These stories were chosen at random and serve to answer the question "who checks vibes best". Next, we compare all models side-by-side on a small, but representative, subset of 10,368 news stories and summarize our findings.
I'd like to acknowledge the support of Fundamental Group in the making of this post and, in particular, Jeanne Daniel who helped conduct this analysis. I also want to thank our two December holiday interns - Moabi and Deon - whose project on sentiment model distillation we will discuss next week.
Table of Contents
- Background
- Dataset
- Models
- LLM Prompt
- Results
- Discussion
- News Steps
- Downloads
Background
When ChatGPT launched it quickly became clear that a new state of the art had been achieved across many natural language processing (NLP) tasks. It's fair to say that it upended decades of work and rewrote the playbook. I too had to improvise, adapt and overcome. Since then, the name of the game has been "large language models" and you either played or became irrelevant.
One of my favorite patterns in this new post-LLM world is prompting LLMs to label documents and then distilling that capability into smaller, faster, and cheaper models with better guarantees. For those of you who don't know, data labelling is when you assign documents to classes based on their contents. Consider news as an example. Here are some of labels we care about:
- Sentiment - is a news story Positive, Neutral, or Negative?
- Forward Looking - is this backward looking or forward looking?
- Category - is this a story about M&A or a Charitable Donation?
- Political Bias - is this story left-leaning or right-leaning?
- Journalistic Beat - is this an opinion piece or investigative?
Etcetera. From what we have seen the most interesting signals stem from the intersection of one or more classifications. For example, using our system it is possible to ask extremely nuanced questions of the data like:
Is the volume of positive M&A news associated with Microsoft increasing or decreasing relative to the volume of negative M&A news?
Or,
Is the sentiment of forward-looking news related to the phrase 'analyst coverage' for General Motors better than that of Ford?
In order to answer these questions, you not only need a lot of data (because the intersection shrinks quickly); you also need what I like to call rich datasets. What are rich datasets? They are datasets where everything that ought to be labelled is. Put differently, rich datasets are actually useful to your quants, analysts, data scientists, and software engineers. Poor datasets are not.
In the past getting labels was time consuming and expensive. Either you paid per label from sketchy services like Mechanical Turk or you dedicated a month or two to doing it yourself. Now there is a better way. We prompt LLMs. For the rest of this post, we will be focused on sentiment classification but please keep in mind that the same approach also works for other NLP classification tasks.
Dataset
Whether you are training or testing machine learning models, it is extremely important that your dataset is representative of what your model will encounter in the real world. Fortunately, our index makes this much easier to do.
- To maximize dataset representation, we made sure it contains:
- News from all years between 2014 and 2023.
- News from all 30 Nosible news categories.
- News from all 145 industries in Nosible.
- And to maximize dataset quality, we only accept news that:
- Comes from a financial news source.
- Is accepted as related to a given company.
- Is not a duplicate of another story.
- Does not originate from an AI-generated site.
- Was covered by 3+ independent publishers.
- Has a title between 5 and 25 words.
- Has a description between 5 and 50 words.
In practical terms this boiled down to running the following SQL query in a nested for loop and then extracting data for the keys that matched.
sql_filter=f"""
SELECT key, media_coverage FROM engine
WHERE date>='{year + 0}-01-01'
AND date<='{year + 1}-01-01'
AND nosible_category='{category_name}'
AND industry='{industry}'
AND source_language_rank>=0.50
AND source_variance_rank>=0.50
AND accepted=true
AND apex_story=true
AND source_is_banned=false
AND media_coverage>=3
AND title_num_words>=5
AND title_num_words<=25
AND description_num_words>=10
AND description_num_words<=50
ORDER BY media_coverage DESC LIMIT 10
"""SQL filter used to produce a high-quality representative dataset of our full News Corpus.
Using this filter, we carved out three datasets:
nosible-news-small[10,368 records] - Contains the biggest story from each overlapping intersection of year, category, and industry.nosible-news-medium[22,422 records] - Contains the biggest 3 stories from each overlapping intersection of year, category, and industry.nosible-news-large[43,324 records] - Contains the biggest 5 stories from each overlapping intersection of year, category, and industry.
Here "biggest" can be defined as - the story that was the most widely reported on or covered by independent publishers at the same time. We find that this is a very good proxy for how impactful (and real) a news story is.
Each dataset contains the following fields:
- Headline - The headline of the news story.
- Description - The Lede or SEO description from the page.
- Category - The category we assigned it to.
- Company - The company to which the story is linked.
- Sector - The GICS sector the linked company.
- Industry - The GICS industry of the linked company.
- Continent - The continent the company is from.
- Country - The country the company is from.
Accompanying this post, we are releasing the nosible-small-news dataset with the sentiment labels assigned by each of the models we evaluated. This data, and the code we used, is available for download at the end of this blog post.
Models
In this evaluation we tried to include a good mixture of old-school lexicon-based sentiment models, pre-LLM sentiment models, and multiple LLMs. What follows is a list of the models we included and a brief description of each.
Random [N/A]
Given a sentence the random classifier returns a -1 (Negative), 0 (Neutral), or 1 (Positive) label with equal probability. I included a random model because they are always useful for computing post-test probabilities (left to the reader).
TextBlob [2013]
TextBlob is a useful Python library for text processing. It uses a lexicon of words with associated sentiment scores to label the polarity of sentences. We tested TextBlob using 3x thresholds for the polarity score (0.15, 0.30, and 0.45).
VADER [2014]
VADER (Valence Aware Dictionary and sEntiment Reasoner) is a lexicon and rule-based sentiment analysis model. Given a sentence it computes a compound score that measures sentiment. We tested it with 3x thresholds as well.
Flair [2019]
Flair is another useful Python library for various NLP tasks. Their pretrained sentiment analysis model uses distilBERT embeddings. Unfortunately, it only outputs two labels - Positive or Negative - so we needed to rejig it.
To get Flair to output three classes we looked at the probability assigned to the best label and only accepted that label if the probability crossed a threshold. We tested 3x values for this threshold - 70%, 80%, and 90% confidence.
FinBERT [2019]
FinBERT is a well-known BERT-based model fine-tuned on financial documents. It was trained to perform three class financial sentiment classification. We used the implementation available on Hugging Face here.
SigmaFSA [2022]
We couldn't find much on this model, but it looks like a fine-tuned version of Financial BERT (not FinBERT) trained to perform three class financial sentiment classification. We used the implementation available on Hugging Face here.
FinBERT Tone [2023]
In 2023 a few finetuned variants of FinBERT were released including ones for ESG, forward looking statement detection, and sentiment. The sentiment one is called FinBERT Tone. Again, we used the Hugging Face implementation.
GPT 3.5 Turbo [2022]
This is the "turbo" version of the original GPT 3.5 model that powered ChatGPT. All of the LLM-based classifiers were given the same prompt. We accessed this model using LangChain. More details on the prompt are given below.
Text-Bison [2023]
Text-Bison is one of the PaLM 2 models that Google launched in 2023. This model is optimized for natural language problems and can be accessed through Google Cloud Platform. We kept all the hyperparameters to their defaults.
Text-Unicorn [2023]
Text-Unicorn is the largest PaLM 2 model. This model is bigger, more capable, and more expensive than Bison. Again, it can be accessed through Google Cloud Platform. We kept all the hyperparameters to their defaults.
GPT 4 [2023]
GPT-4 is the successor model to GPT-3.5. I was made available by OpenAI last year and has demonstrated far superior capabilities across a wide variety of natural language tasks. We accessed GPT-4 through the OpenAI API.
GPT 4 Turbo [2023]
GPT-4-Turbo is a more efficient and more cost-effective version of GPT-4. I was made available by OpenAI at the end of last year. We accessed GPT-4-Turbo through the API. Specifically, we used the gpt-4-1106-preview model.
Gemini-Pro [2023]
Gemini is another suite of large language models released by Google. In this suite there is Gemini-nano, Gemini-pro, and Gemini-ultra. We only have access to Gemini-pro through Google Cloud so we could only include that one.
Future Steps
The blog was getting too big, so we stopped at that. In the future we want to follow up with an evaluation of the new Phi-2 LLM from Microsoft as well as Open Source LLMs including various Llama-2, Falcon, and Mistral variants. If you would like to help out, you can reach me at stuart@nosible.com.
P.S. If you're reading this and you work at Google or X - I really want to benchmark Gemini-nano, Gemini-ultra, and Grok on this task. 🧐
LLM Prompt
When it comes to LLMs, good prompting is crucial. To maximize instruction following ability and accuracy we leveraged few-shot prompting.
Zero-shot prompting involves asking an LLM to perform a task unseen. In other words, the LLM is not given any examples of what success or failure looks like. Few-shot prompting, on the other hand, involves asking an LLM to study a few handpicked examples and then, based on what it learns, perform a task.
Okay, with that said, here's the few-shot prompt we used for this post. This prompt was used for all of the evaluated LLMs with zero modifications.
You are a sentiment classification AI.
1. You are only able to reply with POS, NEU, or NEG.
2. When you are unsure of the sentiment, you MUST reply with NEU.
Here are some examples of correct replies:
Story: Unexpected demand for the new XYZ product is likely to boost earnings.
Reply: POS
Story: Sales of the new XYZ product are inline with projections.
Reply: NEU
Story: Company releases profit warning after the sales of XYZ disappoint.
Reply: NEG
Story: Following better than expected job numbers, the stock market rallied.
Reply: POS
Story: The stock market ended flat after job numbers came in as expected.
Reply: NEU
Story: A large spike in unemployment numbers sent the stock market into panic.
Reply: NEG
Story: XYZ stock soared after the FDA approved its new cancer treatment.
Reply: POS
Story: XYZ will announce results of its cancer treatment on the 15th of July.
Reply: NEU
Story: Following poor results, the FDA shuts down trials of XYZ cancer treatment.
Reply: NEG
Okay, now please classify the following news story:
Story: {story}
Reply: Results
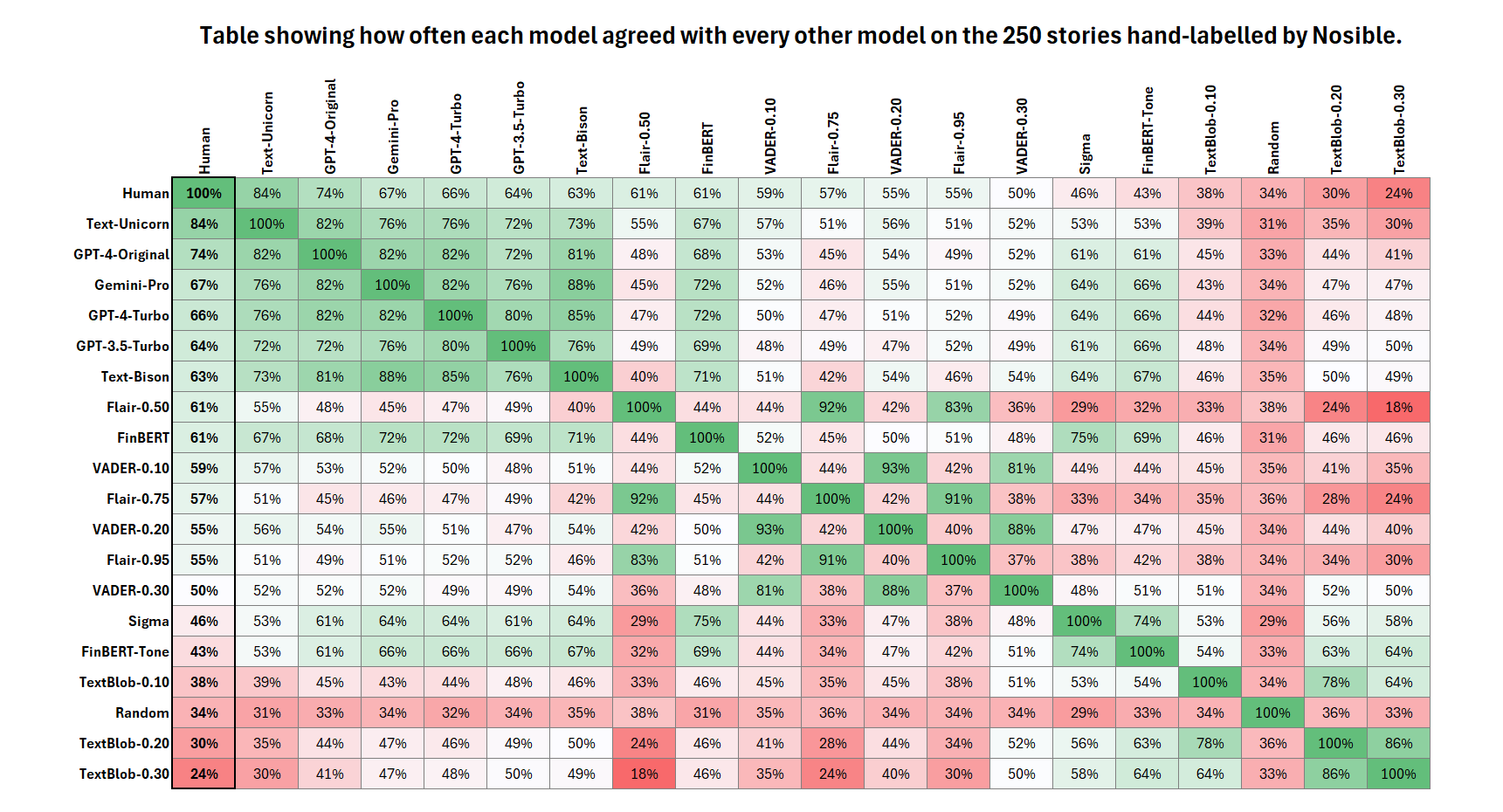
Agreement Matrix - Hand Labelled News
The matrix below shows the percentage of times that each model agreed with every other model across all three classes. The rows and columns have been ordered by how much the model agreed with the hand-labeled human results.
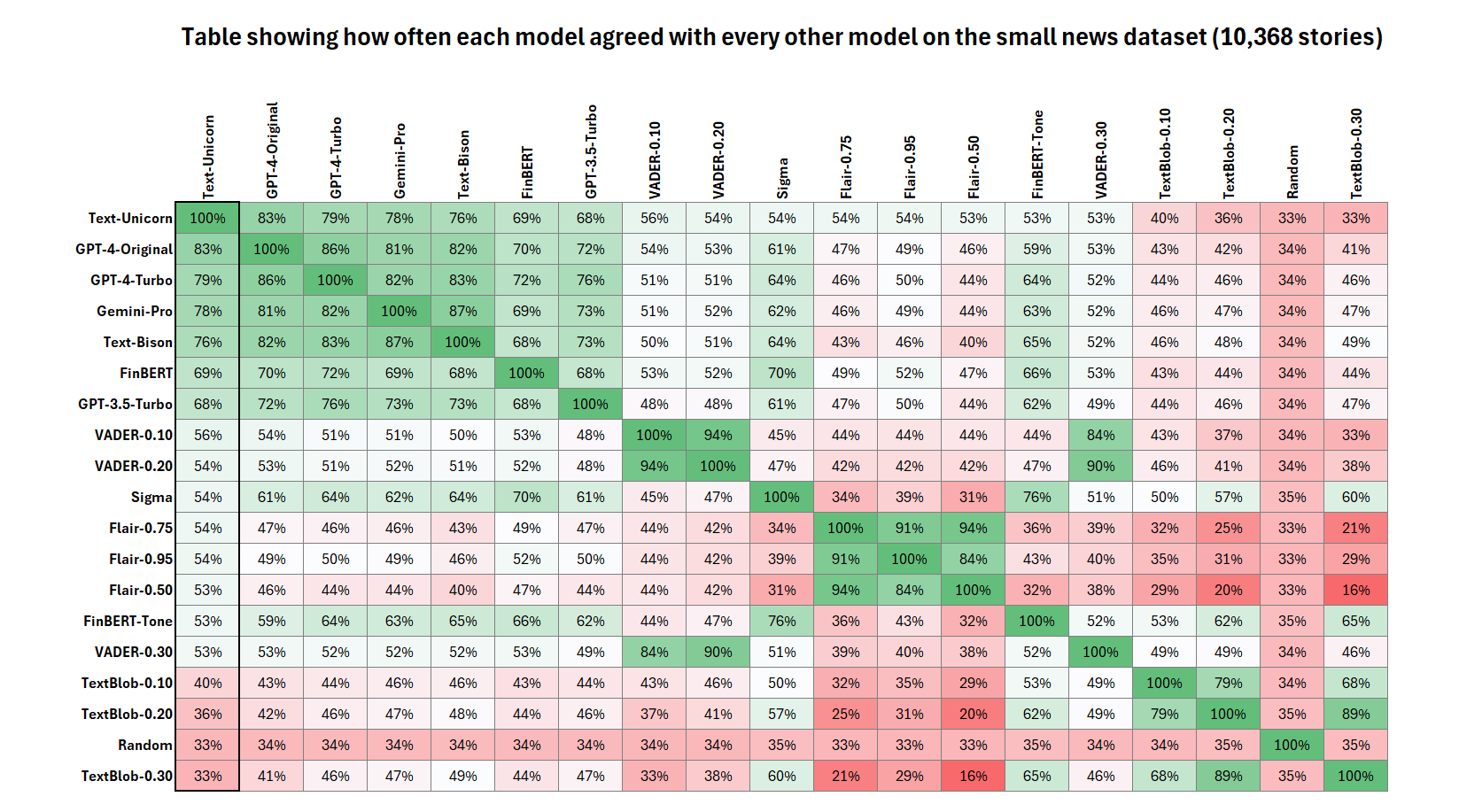
Agreement Matrix - Small News Dataset
The matrix below shows the percentage of times that each model agreed with every other model across all three classes. Here the rows and columns have been ordered by how much they agreed with the best model above - Text-Bison.
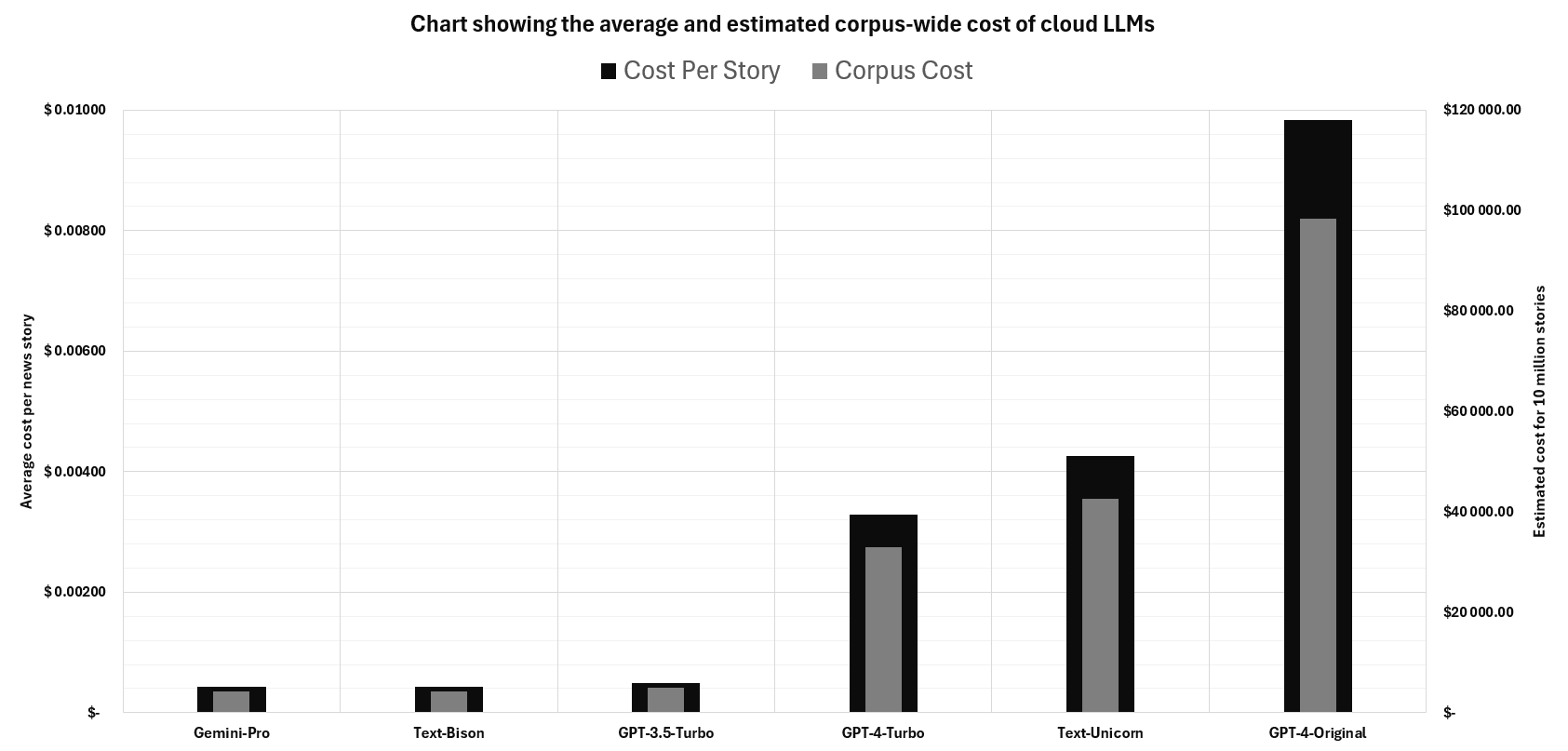
Cloud LLMs - Small News Dataset Costs
The bar chart below shows the average cost incurred per news story labeled as well as the estimated total cost incurred if we used that model to label 10 million news stories (our corpus contains more documents than this already btw 🫢).
Discussion
Firstly, sentiment classification is not obvious. This is especially true for financial news which often involves multiple entities engaged in complex ways. We went back and forth between ourselves on more than one of the 250 stories we labeled. That said, benchmarking against human labels is the best that we can do.
With that disclaimer out of the way, here are some interesting observations:
Cloud-Based LLMs win, but at what cost?
- First place went to the Unicorn PaLM-2 LLM from Google. It assigned the same sentiment as we did an incredible 84% of the time!
- GPT-4 came second. It agreed with us 74% of the time. This is actually 8% more often than GPT-4-Turbo agreed with our sentiment labels.
- GPT-4 and GPT-4-Turbo were (perhaps not too surprisingly) different, and GPT-4-Turbo performed worse than the OG version of GPT-4.
- Gemini-Pro and Bison have the same pricing model. If we were choosing between the two for this task, we would choose Gemini-Pro.
- Given that Gemini-Pro beat Bison, is it possible that Gemini-Ultra would beat Unicorn? This is speculative, but I'd happily wager on it.
- GPT-4-Turbo was 2.98x cheaper than GPT-4. The average cost per story using GPT-4 was \$0.00983 versus\$0.00329 using GPT-4-Turbo.
- Whilst their performance is exceptional, we believe that cloud based LLMs are far too expensive at scale for the majority of organizations.
FinBERT held up reasonably well.
- If ~69% accuracy is okay, then you are better off using FinBERT than GPT-3.5. It is open source and agrees with Unicorn the same amount.
- FinBERT-Tone appears to be a regression rather than an improvement. It only agreed with Unicorn 53% of the time vs. FinBERT's 69%.
At 10 years old VADER still kicks!
- VADER with a threshold of 0.10 agreed with Unicorn 56% of the time. This is far better than TextBlob which was very nearly random.
- At 56% accurate VADER is not good, but it is 339x faster than FinBERT and may still have a place in real-time trading environments.
Flair, SigmaFSA, and FinBERT-Tone
- Despite being far more computationally expensive than VADER, Flair, SigmaFSA, and FinBERT-Tone did not outperform it. Yikes.
- Our guess is that these models are probably overfitted to their training datasets or to their domains and are simply not generalizing.
Next Steps
In our next blog post we will show how the performance of massive cloud-based LLMs like GPT-4 and PaLM-2 Unicorn can be distilled into smaller, faster, and cheaper models with better functional and non-functional guarantees.
Further down the line we would also like to follow this blog post up with a side-by-side comparison of various open-source large language models. If that sounds interesting to you, we are looking for collaborators for that project.
And that's all folks. We are building in public this year so if you liked this content and would like to see more of it, sign up to receive email updates when we blog or follow us on twitter. If you want to talk, I'm at stuart@nosible.com.