Can Faceted Search at Web-Scale Self Organize?
Can Faceted Search at Web-Scale Self Organize? As it turns out, yes it can! In this post we outline our new and improved adaptive named entity tagging system!


Introduction
Few things pack more punch than faceted search. Faceted search involves tagging documents in your index with various "facets". Facets could be content categories, geographies, industries, companies, individuals, etc. Then, when a query arrives, you map the query to the most relevant facets and search within them for the most relevant documents. If your classifier is good and your index supports pre-retrieval, you can unlock higher precision and lower latency.
This is a common idea in Ecommerce search engines, and it works quite well ... but one glaring issue exists: what happens when facets are unbounded? Take companies for example. Every day new companies are created by means of formations, mergers, demergers, joint ventures, spin-offs, carve-outs, etc.
In my opinion, an intelligent search engine – especially one built for finance – should be capable of automatically discovering and understanding these events and updating its facets to match reality. It should self-organize. We've been iterating on this problem for a while and I'm excited to share our solution today. But before we get to that, I need to quickly recap how our search engine is architected because, frankly, it is different to most other search engines.
We Are Many
We built a deep learning model that learns how to segment web-scale corpora into near uniformly sized collections that are semantically and lexically coherent. Our last run learned 250,000 collections from 250,000,000 documents.
Each of these collections are turned into their own miniature search engine. They have their own vector index, lexical index, rerankers, classifiers, and more. When a query arrives, we find the best collections using statistical methods and route the query to them. The results from each collection are fused and the best results are returned back to the user. This is unconventional but has massive benefits ... like, for exampe, getting big model performance from tiny models.
Every new document we index is written to the collection it belongs to and every so often those writes are flushed to disk. Larger or most important collections are flushed more frequently and are also more likely to be cached in RAM.
Distilling Agents
Coming back to named entity recognition, here's a cold hard truth: AI agents crush. They can easily reason about named entities like a person does and using anything else today feels kind of like burning a CD - prehistoric.
Unfortunately, AI agents are too slow and too expensive. At the time of writing we are indexing 15,000,000 new web pages every day. That works out to 91 million paragraphs a day, 180 million sentences, and 4.25 billion tokens.
Passing all of that to an AI Agent every day is not tractable. Fortunately, we have found an elegant solution that gets us agentic-level tagging without the exorbitant costs and untenable latencies. Our solution is as follows.
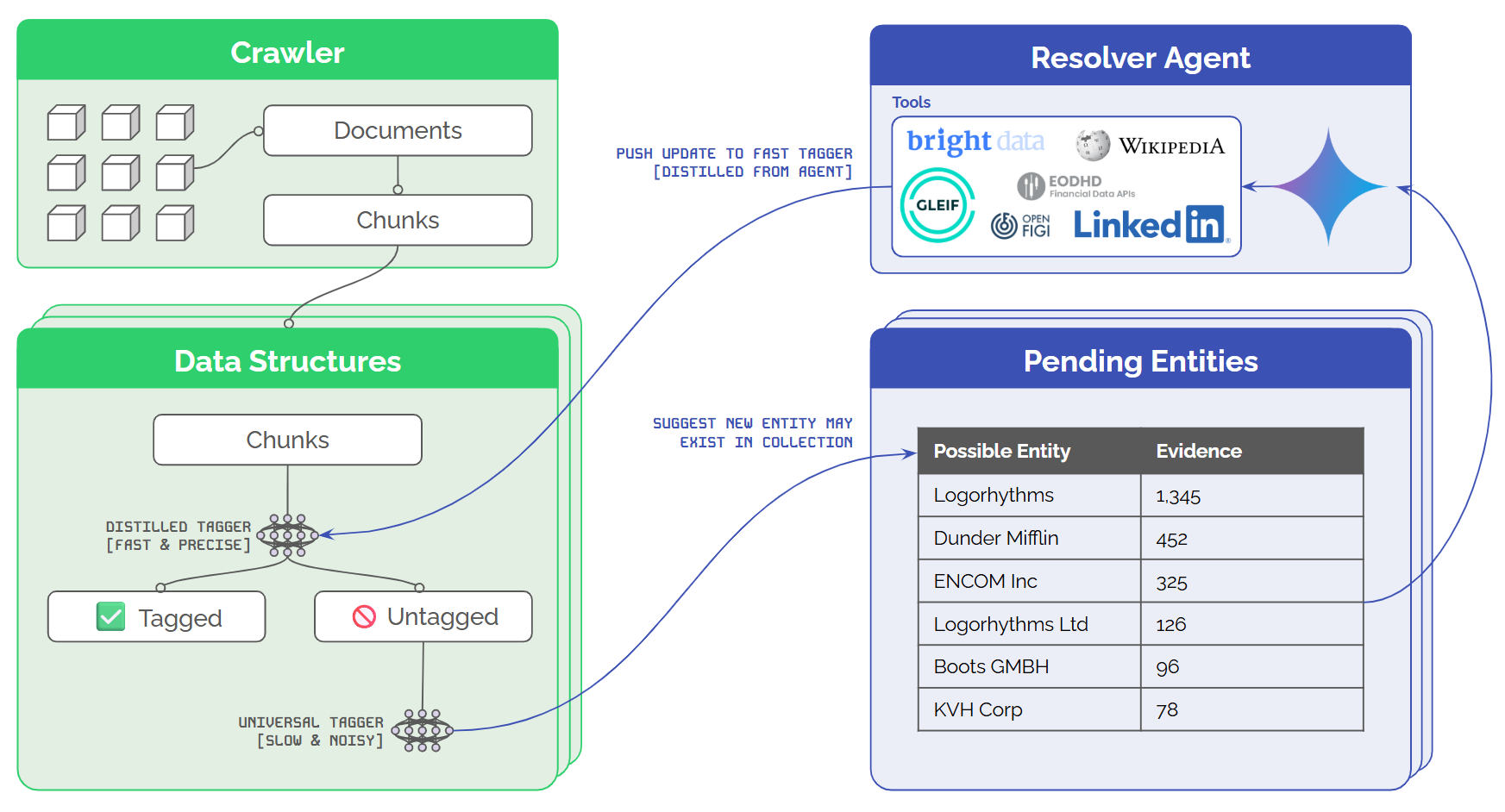
- Each collection contains two taggers:
- An ultra-fast and precise tagger created for that collection using the outputs of the Resolver. This tagger is not neural, it uses Aho-Corasick. It can process data going into a collection in real-time.
- A slow, universal tagger trained to identify named entities in general. This is a neural model, and it sees X% of the data added to each collection. X can be scaled to match compute capacity.
- The slow, universal tagger suggests entities for each collection. Those suggestions are accumulated in a small database and, once a certain threshold is met, the suggestion is sent to the Resolver Agent.
- The Resolver Agent uses a bunch of tools (Search, Wikipedia, LinkedIn, Market APIs, etc.) to work out who this entity is. This step is obviously slow and expensive, but it's also extremely cache friendly.
- If the Resolver Agent accepts the new entity, a new set of patterns is created and sent to the collection(s) that suggested the entity.
- Finally, when the collection is flushed it will check for new patterns. If new patterns are found it will tag all untagged chunks and update the patterns associated with that collection. This happens in seconds.
The pattern is illustrated below:
Why Does It Work?
All of the intelligence exhibited by the Resolver Agent exists in the tokens. After all, the Resolve Agent is "merely" doing next token prediction. Logic dictates that it should therefore be possible to distil a great deal of that intelligence into a simple list of strings and regex patterns. This is not tractable in the general case of course, but it certainly works in specific cases like, for example, JP Morgan.
Here is the data extracted from the web by the Resolver Agent:
{
"name_orig": "JPMorgan Chase",
"name_kgid": "JPMorgan Chase",
"name_wiki": "JPMorgan Chase",
"name_figi": "JPMORGAN CHASE & CO",
"name_eodhd": "JPMorgan Chase & Co",
"name_lei": "JPMORGAN CHASE & CO.",
"ticker_wiki": "JPM",
"ticker_figi": "JPM",
"ticker_eodhd": "JPM.US",
"ticker_serp": "JPM",
"kgid": "kg:/m/01hlwv",
"wiki_qid": "Q192314",
"cik_code": "0000019617",
"isin_code": "US46625H1005",
"cusip_code": "16161A108",
"lei_code": "8I5DZWZKVSZI1NUHU748",
"figi_code": "BBG000DMBXR2",
"open_corp_code": "us_de/691011",
"ein_code": "13-2624428",
"exchange": "New York Stock Exchange",
"mic_code": "XNYS",
"exch_code": "UN",
"ccy_name": "US Dollar",
"ccy_code": "USD",
"ccy_symbol": "$",
"wiki_page": "JPMorgan_Chase",
"website": "http://www.jpmorganchase.com/",
"linkedin": "https://www.linkedin.com/company/jpmorganchase",
"is_company": true,
"is_public": true,
"is_private": false,
"is_delisted": false,
"continent": "North America",
"region": "North America",
"country": "United States",
"country_iso": "US",
"city": "New York City",
"address": "383 Madison Avenue, New York, NY, United States, 10179",
"phone_num": "(212) 270-6000",
"sector": "Financials",
"industry_group": "Banks",
"industry": "Banks",
"sub_industry": "Diversified Banks",
"historical_names": [
"Chase Manhattan International Limited",
"J.P. Morgan and Company",
"Morgan Guaranty Trust Company",
"Drexel, Morgan & Co.",
"Chemical Banking Corporation",
"Chemical Bank of New York",
"The New York Chemical Manufacturing Company",
"Bank One Corporation",
"Banc One Corporation",
"First Bancgroup of Ohio",
"The Bank of the Manhattan Company"
],
"brand_names": [
"JPMorganChase",
"Chase",
"Chase UK",
"Chase Student Loans",
"IndexGPT",
"Quorum",
"JPM Coin",
"J.P. Morgan Workplace solutions"
],
"subsidiaries": [
"Chase Bank",
"JPMorgan Securities, LLC",
"JPMorgan Europe, Ltd.",
"Hambrecht & Quist",
"Robert Fleming & Co.",
"Texas Commerce Bank",
"First Chicago NBD",
"First Chicago Bank",
"Banc One",
"City National Bank of Columbus",
"Purdue National Corporation",
"Bear Stearns",
"Washington Mutual",
"First Republic Bank",
"Collegiate Funding Services",
"ClimateCare",
"J.P. Morgan Cazenove",
"Global Shares",
"Renovite Technologies",
"Viva Wallet",
"Chase Manhattan Bank",
"J.P. Morgan & Co.",
"Bank One",
"Chemical Bank",
"Manufacturers Hanover",
"National Bank of Detroit",
"Providian Financial",
"Great Western Bank",
"Chase National Bank",
"Corn Exchange Bank",
"Guaranty Trust Company of New York",
"JPMorgan Ventures Energy Corporation"
],
"short_wiki": "TRUNCATED",
"summary_raw": "TRUNCATED",
"summary_wiki": "TRUNCATED",
"summary_eodhd": "TRUNCATED",
"markdown_wiki": "TRUNCATED",
"debug_verbose": true
}And here are the unigrams, bigrams, and trigrams distilled from the information the Resolution Agent extracted. We would use these for tagging:
[
"jpm",
"jpmorgan",
"jpmorganchase",
"j.p. morgan",
"chase",
"jpmorgan.com",
"chase.com",
"jpmcoin",
"indexgpt",
"dimon",
"jpmorgan chase",
"j.p. morgan",
"jp morgan",
"j p morgan",
"chase bank",
"nyse jpm",
"jpmorgan securities",
"jpmorgan cazenove",
"jpmorgan europe",
"jpmorgan ventures",
"jpmorgan wealth",
"jpmorgan private",
"jpmorgan asset",
"jpmorgan investment",
"jpmorgan workplace",
"chase uk",
"chase sapphire",
"chase freedom",
"chase ink",
"chase student",
"chase ultimate",
"bear stearns",
"washington mutual",
"first republic",
"bank one",
"chemical bank",
"manufacturers hanover",
"jpmorgan chase & co",
"jpmorgan chase and co",
"jp morgan chase",
"j p morgan chase",
"jpmorgan chase bank",
"jpmorgan securities llc",
"jpmorgan private bank",
"jpmorgan asset management",
"jpmorgan wealth management",
"jpmorgan investment bank",
"jpmorgan workplace solutions",
"chase sapphire reserve",
"chase sapphire preferred",
"chase ultimate rewards",
"chase credit cards",
"chase retail banking",
"house of morgan",
"jamie dimon ceo",
"jpmorgan corporate challenge",
"chase center",
"chase bank",
"jpmorgan securities llc",
"jpmorgan europe ltd",
"hambrecht & quist",
"robert fleming & co",
"texas commerce bank",
"first chicago nbd",
"first chicago bank",
"banc one",
"city national bank of columbus",
"purdue national corporation",
"bear stearns",
"washington mutual",
"first republic bank",
"collegiate funding services",
"climatecare",
"j.p. morgan cazenove",
"global shares",
"renovite technologies",
"viva wallet",
"chase manhattan bank",
"j.p. morgan & co",
"bank one",
"chemical bank",
"manufacturers hanover",
"national bank of detroit",
"providian financial",
"great western bank",
"chase national bank",
"corn exchange bank",
"guaranty trust company of new york",
"jpmorgan ventures energy corporation"
]
Many Benefits
Here are some benefits of this approach:
- Not all entities exist in every collection. And the more coherent your collections, the truer this becomes. In fact, the distribution of entities is extremely sparse in the average case. So, learning collection-specific models saves a tonne of compute cost and minimizes spurious matches.
- The approach is adaptive. We do not start with a hard coded list of entities. We allow each collection to organically discover and suggest new entities for itself thereby allowing it to adapt to change - formations, mergers, demergers, joint ventures, spin-offs, carve-outs, etc.
- We unlock the benefits of agentic search without the prohibitive price tag. Originally, we planned to train our own NER models but, like I said, that kind of feels like burning a CD. Agentic search is here and using anything other than that for this task feels backwards.
LMK if you'd like to see the Resolver Agent in action. Once we have decoupled it from our internal LLM generation tools we will open source it.